Raft 协议(三)—— 集群成员变更

本文介绍 Raft 论文描述的两个 Raft 实践必备技术之一 ——集群成员变更。本文重点讲解 raft 集群如何动态增删节点、集群变更时脑裂的诱因及应对方案。
在前文的理论描述中我们都假设了集群成员是不变的,然而在实践中有时会需要替换宕机机器或者改变复制级别(即增减节点)。一种最简单暴力达成目的的方式就是:停止集群、改变成员、启动集群。这种方式在执行时会导致集群整体不可用,此外还存在手工操作带来的风险。
为了避免这样的问题,Raft 论文中给出了一种无需停机的、自动化的改变集群成员的方式,其实本质上还是利用了 Raft 的核心算法,将集群成员配置作为一个特殊日志从 leader 节点同步到其它节点去。
直接切换集群成员配置
先说结论:所有将集群从旧配置直接完全切换到新配置的方案都是不安全的。
因此我们不能想当然的将新配置直接作为日志同步给集群并 apply。因为我们不可能让集群中的全部节点在“同一时刻”原子地切换其集群成员配置,所以在切换期间不同的节点看到的集群视图可能存在不同,最终可能导致集群存在多个 leader。
为了理解上述结论,我们来看一个实际出现问题的场景,图1对其进行了展现。
阶段a. 集群存在 S1 ~ S3 三个节点,我们将该成员配置表示为 C-old,绿色表示该节点当前视图(成员配置)为 C-old,其中红边的 S3 为 leader。
阶段b. 集群新增了 S4、S5 两个节点,该变更从 leader 写入,我们将 S1 ~ S5 的五节点新成员配置表示为 C-new,蓝色表示该节点当前视图为 C-new。
阶段c. 假设 S3 短暂宕机触发了 S1 与 S5 的超时选主。
阶段d. S1 向 S2、S3 拉票,S5 向其它全部四个节点拉票。由于 S2 的日志并没有比 S1 更新,因此 S2 可能会将选票投给 S1,S1 两票当选(因为 S1 认为集群只有三个节点)。而 S5 肯定会得到 S3、S4 的选票,因为 S1 感知不到 S4,没有向它发送 RequestVote RPC,并且 S1 的日志落后于 S3,S3 也一定不会投给 S1,结果 S5 三票当选。最终集群出现了多个主节点的致命错误,也就是所谓的脑裂。
图2来自论文,用不同的形式展现了和图1相同的问题。颜色代表的含义与图1是一致的,在 problem: two disjoint majorities 所指的时间点,集群可能会出现两个 leader。
但是,多主问题并不是在任何新老节点同时选举时都一定可能出现的,社区一些文章在举多主的例子时可能存在错误,下面是一个案例(笔者学习 Raft 协议也从这篇文章中受益匪浅,应该是作者行文时忽略了。文章很赞,建议大家参考学习):
来源:《Raft 协议详解》知乎某大神
该假想场景类似图1的阶段d,模拟过程如下:
- S1 为集群原 leader,集群新增 S4、S5,该配置被推给了 S3,S2 尚未收到。
- 此时 S1 发生短暂宕机,S2、S3 分别触发选主。
- 最终 S2 获得了 S1 和自己的选票,S3 获得了 S4、S5 和自己的选票,集群出现两个 leader。
图3过程看起来好像和图1没有什么大的不同,只是参与选主的节点存在区别,然而事实是图3的情况是不可能出现的。
注意:Raft 论文中传递集群变更信息也是通过日志追加实现的,所以也受到选主的限制。很多读者对选主限制中比较的日志是否必须是 committed 产生疑惑,回看下在《安全性》一文中的描述:
每个 candidate 必须在 RequestVote RPC 中携带自己本地日志的最新 (term, index),如果 follower 发现这个 candidate 的日志还没有自己的新,则拒绝投票给该 candidate。
这里再帮大家明确下,论文里确实间接表明了,选主时比较的日志是不要求 committed 的,只需比较本地的最新日志就行!
回到图3,不可能出现的原因在于,S1 作为原 leader 已经第一个保存了新配置的日志,而 S2 尚未被同步这条日志,根据上一篇《安全性》我们讲到的选主限制,S1 不可能将选票投给 S2,因此 S2 不可能成为 leader。
两阶段切换集群成员配置(Joint consensus)
最开始 Raft 使用 joint consensus 实现成员变更,raft extended 中也只提到了这种方式,这种方式支持一次变更多个成员,但是复杂一些。
joint consensus 使用一种两阶段方法平滑切换集群成员配置来避免遇到前一节描述的问题。
C-old 为当前的配置,C-new 为目标配置。当 leader 收到成员变更的请求时,会创建一个 C-old-new 的配置(joint consensus),所有节点在接收到配置时就采用新的配置,不用等到 commit。 joint consensus 把新旧配置联系起来:
log entries复制到2个配置的所有节点上;- 使用
C-old或C-old-new配置的节点都可能成为leader; - 处于
C-old-new状态时,必须收到C-old的majority和C-new的majority的同意才能提交或选出leader。
当 C-old-new 被提交之后,创建 C-new 配置,当 C-new 被提交后,整个成员变更结束,不在 C-new 中的节点可以关闭。joint consensus 确保了 C-old 和 C-new 不会同时做决定,保证了 safety。
具体流程如下:
阶段一
- 客户端将 C-new 发送给 leader,leader 将 C-old 与 C-new 取并集并立即apply,我们表示为 C-old,new(
joint consensus)。 - Leader 将 C-old,new 包装为日志同步给其它节点。
- Follower 收到 C-old,new 后立即 apply,当 C-old,new 的大多数节点(即 C-old 的大多数节点和 C-new 的大多数节点)都切换后,leader 将该日志 commit。
阶段二
- Leader 接着将 C-new 包装为日志同步给其它节点。
- Follower 收到 C-new 后立即 apply,如果此时发现自己不在 C-new 列表,则主动退出集群。
- Leader 确认 C-new 的大多数节点都切换成功后,给客户端发送执行成功的响应。
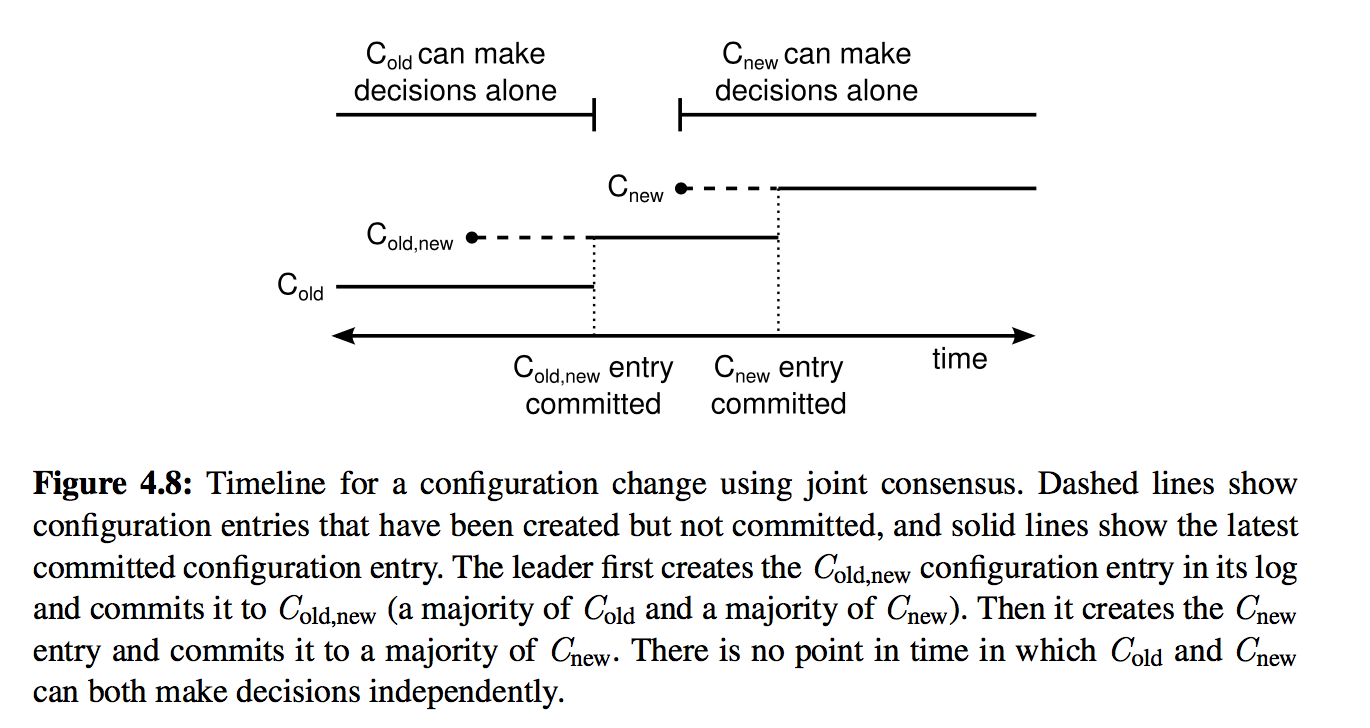
图4展示了该流程的时间线。虚线表示已经创建但尚未 commit 的成员配置日志,实线表示 committed 的成员配置日志。
为什么该方案可以保证不会出现多个 leader?我们来按流程逐阶段分析。
阶段1. C-old,new 尚未 commit
该阶段所有节点的配置要么是 C-old,要么是 C-old,new,但无论是二者哪种,只要原 leader 发生宕机,新 leader 都必须得到大多数 C-old 集合内节点的投票。
以图1场景为例,S5 在阶段d根本没有机会成为 leader,因为 C-old 中只有 S3 给它投票了,不满足大多数。
阶段2. C-old,new 已经 commit,C-new 尚未下发
该阶段 C-old,new 已经 commit,可以确保已经被 C-old,new 的大多数节点(再次强调:C-old 的大多数节点和 C-new 的大多数节点)复制。
因此当 leader 宕机时,新选出的 leader 一定是已经拥有 C-old,new 的节点,不可能出现两个 leader。
阶段3. C-new 已经下发但尚未 commit
该阶段集群中可能有三种节点 C-old、C-old,new、C-new,但由于已经经历了阶段2,因此 C-old 节点不可能再成为 leader。而无论是 C-old,new 还是 C-new 节点发起选举,都需要经过大多数 C-new 节点的同意,因此也不可能出现两个 leader。
阶段4. C-new 已经 commit
该阶段 C-new 已经被 commit,因此只有 C-new 节点可以得到大多数选票成为 leader。此时集群已经安全地完成了这轮变更,可以继续开启下一轮变更了。
以上便是对该两阶段方法可行性的分步验证,Raft 论文将该方法称之为共同一致(Joint Consensus)。
关于集群成员变更另一篇更详细的论文还给出了其它方法,简单来说就是论证一次只变更一个节点的的正确性,并给出解决可用性问题的优化方案。感兴趣的同学可以参考:《Consensus: Bridging Theory and Practice》。
单节点变更(single-server changes)
该算法每次只允许增加或移除一个节点,只有当上一轮成员变更结束,才能开始下一轮,复杂的成员变更转换为多次单个成员变更。 增加或删除一个节点时,新旧配置中构成 majority 的部分必有重叠,不会有单独一部分做出决定,保证了 safety: 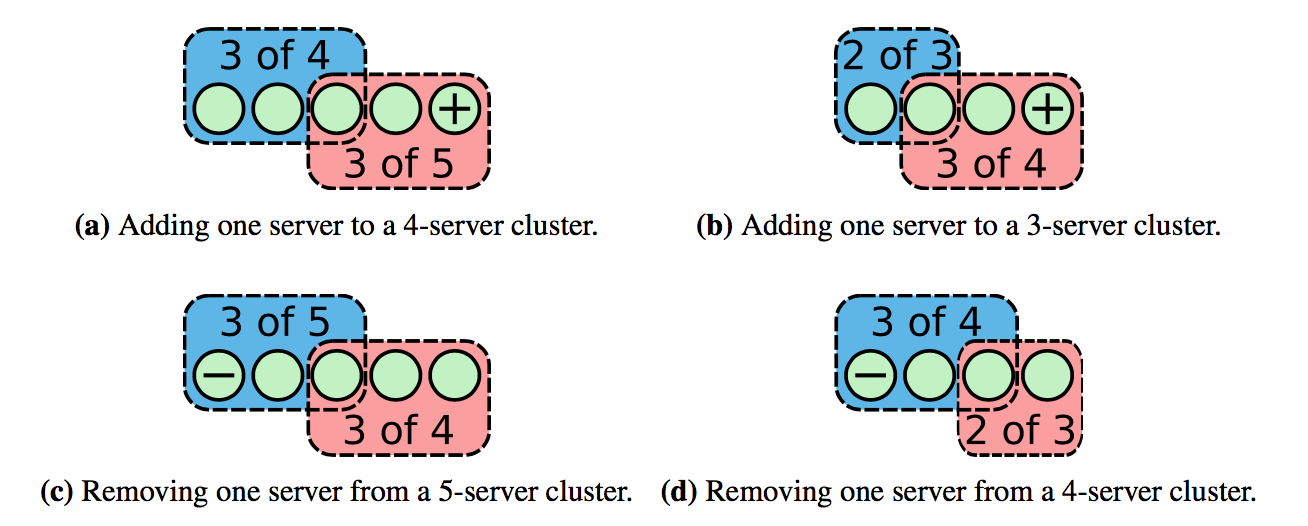
当发起成员变更时,leader 会增加一个特殊的 log entry,然后通过 log replication 复制到其他节点上。raft thesis 中是节点接收到成员变更的 entry 时,就使用 新的配置,当该 entry 被 commit 后,意味着 majority 节点采用了新的配置,该次成员变更结束,可以开始下一轮。采用这种方式,节点配置需要能够回退,因为未 commit 的 entry 有可能被覆盖。
因为节点只有接收到 config change entry 才会改变配置,需要处理不在当前配置内的节点的消息:
- 节点需要接收不在自己集群成员内的
leader的AppendEntries,否则新加入的节点将永远不会加入到集群中(不会接收任何log); - 节点需要给不在自己集群成员内的节点投票,比如给3个节点的集群增加了第4个节点,当
leader挂了需要新增加的节点也可以投票; - 被移除的节点不会收到
heartbeat,可能会超时发起投票影响集群(因为上面第二点),使用check quorum和Pre-Vote可以解决。
etcd/raft 的实现有所不同:只有当成员变更的 entry 被 apply 之后,才使用新的配置(同样需要处理上面的问题)。raft thesis 中写道,但是我没有想到在某种情况下,使用 etcd/raft 的方式会有问题:
It is only safe to start another membership change once a majority of the old cluster has moved to operating under the rules of Cnew. If servers adopted Cnew only when they learned that Cnew was committed, Raft leaders would have a difficult time knowing when a majority of the old cluster had adopted it.
使用 etcd/raft 的方式需要注意: 从2个节点中移除一个时,若有一个节点挂了,则整个集群不可用,但是一般至少使用3副本。
etcd/raft 实现
调用 Node.ProposeConfChange() 来发起成员变更,因为也需要通过 log replication 来提交,所以复用了 pb.Entry,需要进行 marshal:
1 | |
pb.ConfChange 结构如下:
Type: 成员变更操作类型,包括增加节点、删除节点等;NodeId:etcd/raft中使用ID代表节点,ID必须非零且唯一(使用之前使用过的也不行);Context: 可以用来保存节点的地址。1
2
3
4
5
6
7type ConfChange struct {
ID uint64 `protobuf:"varint,1,opt,name=ID" json:"ID"`
Type ConfChangeType `protobuf:"varint,2,opt,name=Type,enum=raftpb.ConfChangeType" json:"Type"`
NodeID uint64 `protobuf:"varint,3,opt,name=NodeID" json:"NodeID"`
Context []byte `protobuf:"bytes,4,opt,name=Context" json:"Context,omitempty"`
XXX_unrecognized []byte `json:"-"`
}
在 raft.StepLeader() 中会判断是否有未完成 config change,若存在,则忽略新的 config change:
1 | |
当 config change 被提交了,调用 Node.ApplyConfChange() 来完成成员变更:
- 调用
raft的接口增加或删除节点:etcd/raft的实现很简单,就是操作raft.prs(NodeId到Progress的映射); - 返回最新的集群结构。 用户根据
config change的类型,决定是关闭节点,还是新建连接。
启动
在启动一个新的集群时,raft.StartNode() 中需要传入集群的 peer list,然后使用 config change 的方式添加节点,使用这种方式把启动时的成员配置和成员变更统一起来,简化了实现:
1 | |
README 中只传入了其他节点的 ID,不包含自己的,应该有问题,peer list 应该包含所有节点的 ID,否则节点的 log 有冲突,新加入节点的成员配置也会出错。
当需要新增一个节点时,首先给集群发起成员变更,然后不用传入 peer list 启动节点,集群配置会在 log replication 过程中同步到新节点:
1 | |
Snapshot
raft 的集群配置通过 log replication 传递,同样也通过 log 来恢复,通过一个个应用 log entry 能够恢复到一致的集群成员配置。之前提到 snapshot 只保存了状态机的状态,为了支持成员变更, snapshot 中需要保存该 snapshot 对应的集群成员配置:
1 | |
Learner
加入新的节点有可能降低集群的可用性,因为新的节点需要花费很长时间来同步 log,可能导致集群无法 commit 新的请求,比如原来有 3 个节点的集群,可以容忍 1 个节点出错,然后新加入了一个节点, 若原先的一个节点出错会导致集群不能 commit 新的请求,直到节点恢复或新节点追上: 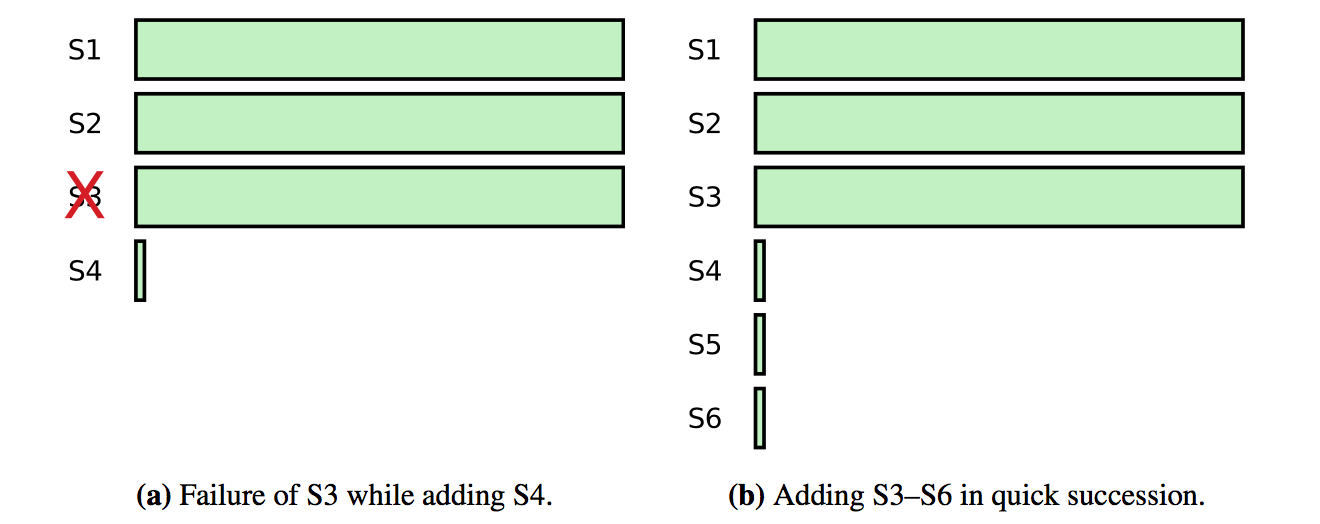
为了避免这个问题,可以引入 learner 状态,新加入的节点设置为 learner 状态,该状态的节点不计在 majority,也就不参与投票和 commit, 当 learner 追上集群的进度时,提升为正常的节点,完成 config change。
etcd/raft 增加了 learner 特性,但是没有投入使用,也没有实现判断 learner 进度。过程和上面类似,只是设置 ConfChangeType 为 ConfChangeAddLearnerNode。etcd/raft 使用 raft.learnerPrs 保存 learner 节点的 NodeId 到 Progress 的映射,当应用成员变更时,调用 raft.addNodeOrLearnerNode() 添加到 raft.learnerPrs 中:
1 | |
当判断 learner 节点追上其他节点,需要提升为正常节点时,需要再发起一次正常的成员变更。只允许 learner 变为 voter,不允许反过来。
learner 节点有如下特性:
当
election timeout时,不会成为candidate发起选举:1
2
3
4func (r *raft) promotable() bool {
_, ok := r.prs[r.id]
return ok
}不会给其他节点投票:
1
2
3
4
5
6
7case pb.MsgVote, pb.MsgPreVote:
if r.isLearner {
// TODO: learner may need to vote, in case of node down when confchange.
r.logger.Infof("%x [logterm: %d, index: %d, vote: %x] ignored %s from %x [logterm: %d, index: %d] at term %d: learner can not vote",
r.id, r.raftLog.lastTerm(), r.raftLog.lastIndex(), r.Vote, m.Type, m.From, m.LogTerm, m.Index, r.Term)
return nil
}不计在
quorum中:1
func (r *raft) quorum() int { return len(r.prs)/2 + 1 }
Leadership transfer
有可能需要移除的节点是 leader,按照 raft thesis 的做法会比较奇怪,leader 需要管理不包含自己的集群,直到提交之后再 step down,可以通过 leadership transfer 将 leadership 转移到其他节点, 然后再移除原先的 leader。leadership transfer 还有其他的用途,比如 leader 所在机器的负载比较高,要转移到低负载机器上;leader 要改变机房实现就近等,同时还能降低选举的影响。
leadership transfer 的流程如下:
leader停止接收新的请求;- 通过
log replication使leader和transferee的log相同,确保transferee能够赢得选举; leader发送TimeoutNow给transferee,transferee会立即发起选举。leader收到transferee的消息会step down。
仍有几个问题需要处理:
transferee挂了: 当leadership transfer在election timeout时间内未完成,则终止并恢复接收客户端请求。transferee有大概率成为下一个leader,若失败,可以重新发起leader transfer。check quorum会使节点忽略RequestVote,需要强制投票。
etcd/raft 实现
调用 Node.TransferLeadership() 发起 leadership transfer:
1 | |
leader 接收到之后会做一些检查,如果有正在进行的 leadership transfer,则终止之前的;检查 transferee 的 ID 等。主要看一下正常的逻辑:
设置
r.electionElapsed = 0,用于检测leadership transfer超时;设置
r.leadTransferee = leadTransferee,表示正在进行leadership transfer;若
transferee的log已经最新,则立刻发送TimeoutNow,否则等到log匹配时,再发送:1
2
3
4
5
6
7
8
9
10
11case pb.MsgTransferLeader:
// ...
// Transfer leadership should be finished in one electionTimeout, so reset r.electionElapsed.
r.electionElapsed = 0
r.leadTransferee = leadTransferee
if pr.Match == r.raftLog.lastIndex() {
r.sendTimeoutNow(leadTransferee)
r.logger.Infof("%x sends MsgTimeoutNow to %x immediately as %x already has up-to-date log", r.id, leadTransferee, leadTransferee)
} else {
r.sendAppend(leadTransferee)
}
leader 不会接收新的客户端请求:
1 | |
当 transferee 的 log 追上时,发送 TimeoutNow:
1 | |
当 transferee 收到 TimeoutNow,调用 raft.campaign(campaignTransfer),会跳过 Pre-Vote 阶段,和正常投票只有一点不同,会设置 Message.Context 用于跳过 check quorum:
1 | |
在其他节点收到携带 Context 的 RequestVote 消息时,会强制投票:
1 | |
leader 在 tickHeartbeat() 中检测 leadership transfer 超时,设置 raft.leadTransferee = None 终止:
1 | |
至此我们已经将 Raft 论文中的内容基本讲解完毕了。《In Search of an Understandable Consensus Algorithm (Extended Version)》 毕竟只有18页,更加侧重于理论描述而非工程实践。如果你想深入学习 Raft,或自己动手写一个靠谱的 Raft 实现,《Consensus: Bridging Theory and Practice》 是你参考的不二之选。