6.824 Lab 2 - Raft
The source code of this Lab is Here
Background
Consensus algorithms are vital in large-scale, fault-tolerant systems because they enable a set of distributed/replicated machines or servers to work as a coherent group and agree on system state, even in the presence of failures or outages.

There are basically two types of consensus algorithms:
- Byzantine Fault Tolerance Consensus Algorithm
- Non-byzantine Fault Tolerance Consensus Algorithm
Byzantine Fault Tolerance(BFT) is the feature of a distributed network to reach consensus(agreement on the same value) even when some of the nodes in the network fail to respond or respond with incorrect information. The objective of a BFT mechanism is to safeguard against the system failures by employing collective decision making(both – correct and faulty nodes) which aims to reduce to influence of the faulty nodes. BFT is derived from Byzantine Generals’ Problem.
The Byzantine Generals Problem is a game theory problem, which describes the difficulty decentralized parties have in arriving at consensus without relying on a trusted central party. Only decentralized systems face the Byzantine Generals problem, as they have no reliable source of information and no way of verifying the information they receive from other members of the network. The problem was explained aptly in a paper by LESLIE LAMPORT, ROBERT SHOSTAK, and MARSHALL PEASE at Microsoft Research in 1982.
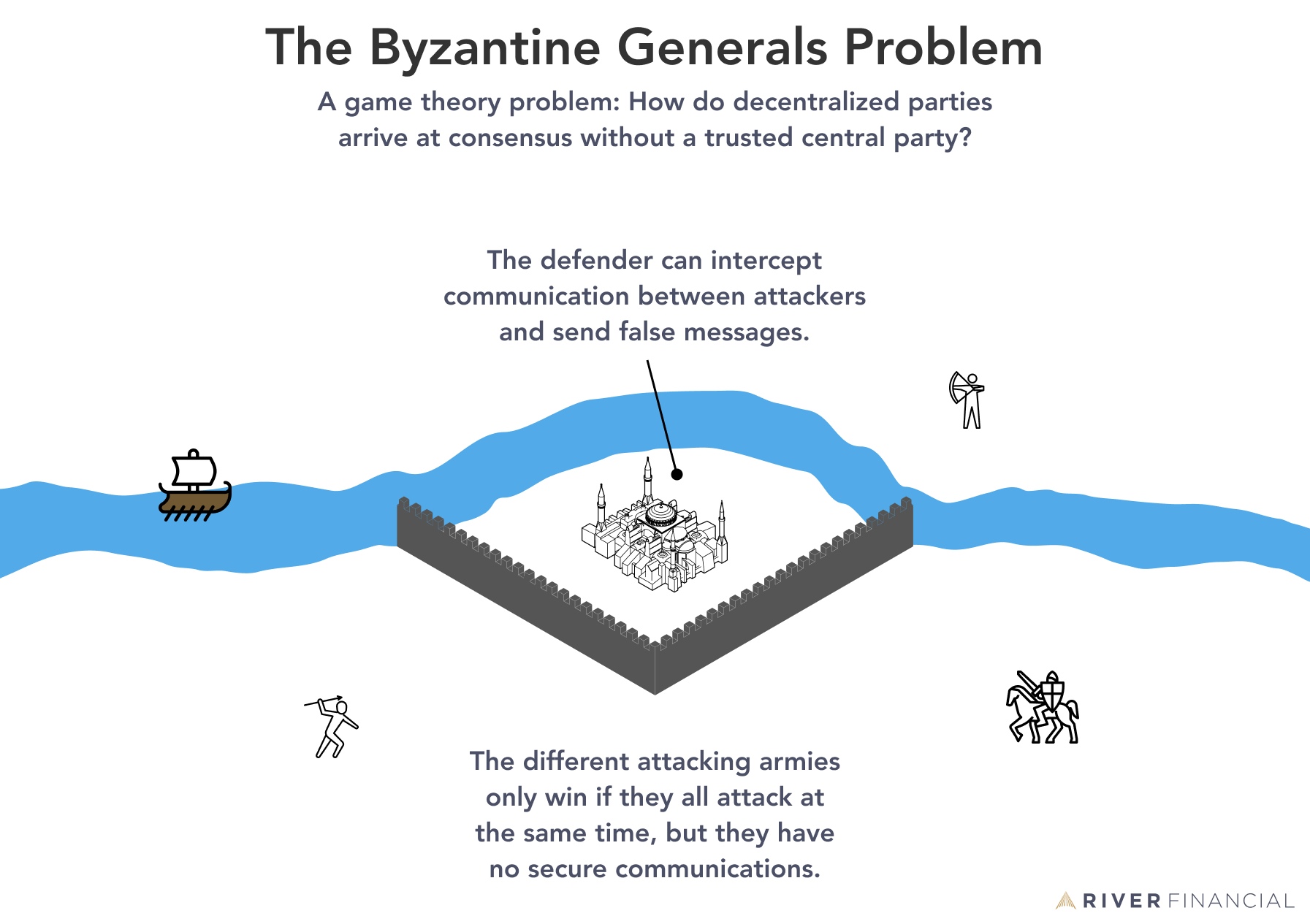
So what I want to emphasize is that the Byzantine Generals problem describes the most difficult and complex distributed fault scenario. In addition to faulty behavior, there is also a scenario of malicious behavior. In the presence of malicious node behavior (such as in the blockchain technology of digital currencies), we must apply Byzantine Fault Tolerance.
Leslie Lamport constructed two solutions to the Byzantine Generals Problem:
- A SOLUTION WITH ORAL MESSAGES
- A SOLUTION WITH SIGNED MESSAGES
Besides, other commonly used BFT includes:
- PBFT(practical Byzantine Fault Tolerance)
- PoW(Proof-of-Work).
While in a distributed computing system, the most commonly used non-Byzantine fault-tolerant algorithm is Crash Fault Tolerance (CFT). CFT solves the consensus problem in the scenario where there is a fault in the distributed system, but no malicious node.
The commonly used CFT includes:
Raft produces a result equivalent to (multi-)Paxos, and it is as efficient as Paxos. In this lab we'll implement Raft, a replicated state machine protocol.
Introduction
We should follow the design in the extended Raft paper, with particular attention to Figure 2. We'll implement most of what's in the paper, including saving persistent state and reading it after a node fails and then restarts. We will not implement cluster membership changes (Section 6).
We may find this guide useful, as well as this advice about locking and structure for concurrency.
To help us to understand Raft algorithm, this working draft visualize the data flow of consensus algorithm and especially Raft algorithm.
Raft decomposes the consensus problem into three relatively independent subproblems: Leader Election, Log Replication in the state machine, and Cluster Membership Changes. In this lab, we will only implement the first two parts, with two other essential techniques for Raft practice: Persistence and Log Compaction.
Lab Code Structure
A service calls Make(peers,me,…) to create a Raft peer. the ports of all the Raft servers (including this one) are in peers[]. this server's port is peers[me]. all the servers' peers[] arrays have the same order. persister is a place for this server to save its persistent state, and also initially holds the most recent saved state, if any. Make() must return quickly, so it should start goroutines for any long-running work.
applyCh is a channel on which the tester or service expects Raft to send ApplyMsg messages. The service expects your implementation to send an ApplyMsg for each newly committed log entry to the applyCh channel argument to Make(). you'll want to send two kinds of messages to the service (or tester) on the same server: command and snapshots. set CommandValid to true to indicate that the ApplyMsg contains a newly committed log entry and set CommandValid to false for snapshots.
Start(command interface{}) asks Raft to start the processing to append the command to the replicated log. Start() should return immediately, without waiting for the log appends to complete.
1 | |
this lab has also provided a diagram of Raft interactions that can help clarify how your Raft code interacts with the layers on top of it:
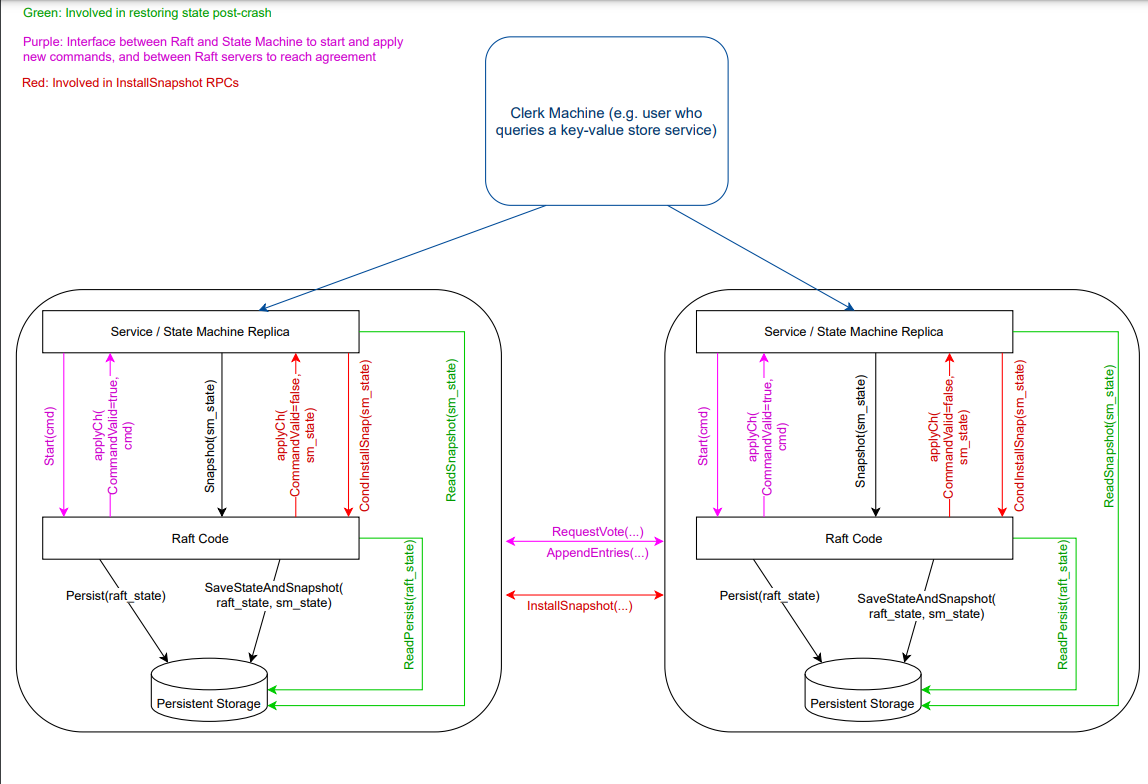
Combining the interactions diagram and test code, we can see how our Raft code works as a whole:
The test functions call func make_config(t *testing.T, n int, unreliable bool, snapshot bool) *config to create a raft service, in which, it calls Make(peers,me,…).
The service calls func (cfg *config) one(cmd interface{}, expectedServers int, retry bool) int to do a complete agreement, in which, it calls rf.Start(cmd) to append the command to the replicated log.
Logging
In order to debug distributed systems, We will make Go print a boring log with a specific format for each peer service. Here I use go-hclog as the logger to output formatted log in a file for each peer. It prints the message along with the topic and the amount of milliseconds since the start of the run.
1 | |
1 | |
Locking Advice
To avoid Livelocks, I use Golang Atomic as much as possible and fetch all the variables at the very beginning of each function. And try to use fine-grained lock instead of Coarse-Grained Lock (such as using sync.Mutex to lock the whole function). And also copy-on-write technich when dealing with the Raft logs.
Besides, to prevent thread getting blocked, we can add time limit to Go Select Statement for asynchronous nofitication:
1 | |
To aovid deadlock, we can prevent Deadlock by eliminating Circular wait condition: all of the functions request the resources in an increasing order of numbering. For example, lastLock sync.Mutex first and then logsLock sync.RWMutex.
Data Structure Design
As for the general structure, the tables in Raft paper are very clear in Figure 2, and we only need to add some details.
Server State
Firstly, we define some enum constants to represent the server node status:
1 | |
To represent the state of all the servers, we define raftState to maintain various state variables:

1 | |
In Go, one can use structs for inheritance. For object-oriented programming, we can compose using raftState to form our Raft peer struct:
1 | |
AppendEntries RPC
One important things to define PRC struct is that go RPC sends only struct fields whose names start with capital letters. Sub-structures must also have capitalized field names (e.g. fields of log records in an array). The labgob package will warn you about this; don't ignore the warnings.

1 | |
Another important things here is that, for all of the data structure, attaching a String() function to a named struct allows us to convert a struct to a string. This will help me a lot during debugging!
RequestVote RPC

1 | |
InstallSnapshot RPC
In the Raft paper, Snapshots are split into chunks for transmission; this gives the follower a sign of life with each chunk, so it can reset its election timer.

But here, for simplicity, we don't split Snapshots into several chunks. So we don't use the variable offset and done in this lab.
1 | |
RPC Handler
Our Raft peers should exchange RPCs using the labrpc Go package (source in src/labrpc). The tester can tell labrpc to delay RPCs, re-order them, and discard them to simulate various network failures.
We use labrpc.ClientEnd.Call() to send a request and waits for a reply. Call() is guaranteed to return (perhaps after a delay) except if the handler function on the server side does not return. Thus there is no need to implement your own timeouts around Call().
The labrpc package simulates a lossy network, in which servers may be unreachable, and in which requests and replies may be lost. Call()sends a request and waits for a reply. If a reply arrives within a timeout interval, Call() returns true; otherwise Call() returns false. Thus Call() may not return for a while. A false return can be caused by a dead server, a live server that can't be reached, a lost request, or a lost reply.
Since Call() may return for a long time, which means the possibility of outdated PRC response. And we apply Go Channel as a medium for goroutines, for example background goroutine that kicking off leader election periodically by sending out RequestVote RPCs, to communicate with each other. So we should take this condition into account: Peer 1, for example, sent the RequestVote RPCs during the its leader lease time and got blocked in rf.peers[server].Call(...) clause, but when RPC returned, peer 1 has already been the follower, which means this PRC response is outdated and some of the channels for receiving data have already been cloesed!
One way to handle this potential bug is to restrict blocked time in RPC handler:
1 | |
Server Behavior
At any given time each server is in one of three states: leader, follower, or candidate.
- Followers are passive: they issue no requests on their own but simply respond to requests from leaders and candidates.
- The leader handles all client requests (if a client contacts a follower, the follower redirects it to the leader).
- Candidate is used to elect a new leader.
So the whole Raft module is constructed in a main loop:
1 | |
What is left is to code all the behaviors of different states for one server. Figure 2 describes the algorithm more precisely:

Leader Election
Raft uses a heartbeat mechanism to trigger leader election. When servers start up, they begin as followers running code rf.runFollower(). A server remains in follower state as long as it receives valid RPCs from a leader or candidate.
If a follower receives no communication over a period of time called the election timeout (in code we use HeartbeatTimeout to represent), then it assumes there is no viable leader and begins an election to choose a new leader. After the node elects itself as a candidate, the function rf.runCandidate()executes.
runFollower()
Each follower will have a random time to see if the leader's contact has been received within a certain period of time(HeartbeatTimeout). If the time from the last contact exceeds the timeout time, it will enter the candidate state:
1 | |
1 | |
Every time the follower receives the leader's HeartBeat, AppendEntries, InstallSnapshot and other operations, the LastContact time will be updated:
1 | |
1 | |
1 | |
1 | |
runCandidate()
The core logic of the candidate is in the electSelf() function, where the candidate will first increase its own term, and then send RequestVote RPC in parallel to each of the other servers in the cluster., and finally become the leader when the number of votes is greater than 1/2 of the number of nodes.
1 | |
The candidate process is as follows:
- send RequestVote RPC to all nodes: elect yourself as the leader and wait for the replies from all other nodes.
- If in the replies of other nodes, the term of their service is greater than the term of your own (
vote.Term > r.getCurrentTerm()), indicating that your election is behind and you are not eligible for the leader, so you set your status to follower and update term at the same time. Finally exit the candidate process. - If the replies from other nodes agree with your own proposal, your votes will be increased by one. If the number of votes is greater than half of the nodes, it means that your are successfully elected as the leader, and your status is updated to the leader. Finally exit the candidate process.
- If the election request times out, exit the candidate process directly.
1 | |
Safety Argument
Generally, consensus algorithms need to satisfy three basic properties, namely agreement, integrity, and termination. These three basic properties can also be summarized into two, namely Liveness and Safety. Safety refers to agreement and integrity, which means that the processed proposal comes from the correct node, and the final state of the correct node can always be consistent.
Raft ensures this security by adding some additional restrictions and measures to the process of leader election and log replication:
Make sure the election timeouts in different peers don't always fire at the same time, or else all peers will vote only for themselves and no one will become the leader.
The system should satisfies the following timing requirement:
broadcastTime ≪ electionTimeout ≪ MTBFThe paper's Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds.
Because the tester limits you to 10 heartbeats per second, we will have to use an election timeout larger than the paper's 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five seconds.
To randomize the election timeouts, we may find Go's rand useful:
1
2
3
4
5
6
7
8// randomTimeout returns a value that is between the minVal and 2x minVal.
func randomTimeout(minVal time.Duration) <-chan time.Time {
if minVal == 0 {
return nil
}
extra := time.Duration(rand.Int63()) % minVal
return time.After(minVal + extra)
}we can use it like this:
1
heartbeatTimer := randomTimeout(r.config().HeartbeatTimeout)Here we give two recommended parameter settings:
ElectionTimeout: 150ms-300ms, HeartbeatTimeout: 50ms
ElectionTimeout: 200ms-400ms, HeartbeatTimeout: 100ms
1
2
3
4
5
6
7
8
9
10
11
12func DefaultConfig() Config {
id := generateUUID()
return Config{
HeartbeatTimeout: 100 * time.Millisecond,
ElectionTimeout: 200 * time.Millisecond,
CommitTimeout: 50 * time.Millisecond,
LeaderLeaseTimeout: 100 * time.Millisecond,
LogLevel: "DEBUG",
LocalID: ServerID(id),
LogOutput: os.Stderr,
}
}
Log Replication
Log replication is initiated by the leader and executed in the function rf.runLeader().
The Leader process is as follows:
Start a replication routine for each peer, calling
r.startStopReplication()to perform log replication.Sit in the leader loop until we step down, calling
r.leaderLoop().In
leaderLoop(), we periodically check out leader state:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18for r.getState() == Leader {
...
case <-lease:
// Check if we've exceeded the lease, potentially stepping down
maxDiff := r.checkLeaderLease()
// Next check interval should adjust for the last node we've
// contacted, without going negative
checkInterval := r.config().LeaderLeaseTimeout - maxDiff
if checkInterval < minCheckInterval {
checkInterval = minCheckInterval
}
r.logger.Info("check lease time","checkInterval",checkInterval)
// Renew the lease timer
lease = time.After(checkInterval)
}When we exit leader state, reset
lastContact(callingr.setLastContact()). Since we were the leader previously, we update our last contact time when we step down, so that we are not reporting a last contact time from before we were the leader. Otherwise, to a client it would seem our data is extremely stale.
The core function to perform log replication is startStopReplication():
Start a new goroutine, calling
replicate()to perform log replication for each node except the leader.The status of each node's AppendEntries RPC is saved through the object
followerReplication:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// followerReplication is in charge of sending snapshots and log entries from
// this leader during this particular term to a remote follower.
type followerReplication struct {
Term uint64
LeaderId int32
PrevLogIndex uint64
PrevLogTerm uint64
LeaderCommit uint64
Entries []Log
EntriesLock sync.RWMutex
// getLastContact is updated to the current time whenever any response is
// received from the follower (successful or not). This is used to check
// whether the leader should step down (Raft.checkLeaderLease()).
LastContact time.Time
// LastContactLock protects 'getLastContact'.
LastContactLock sync.RWMutex
// failures counts the number of failed RPCs since the last success, which is
// used to apply backoff.
Failures uint64
// stopCh is notified/closed when this leader steps down or the follower is
// removed from the cluster. In the follower removed case, it carries a log
// index; replication should be attempted with a best effort up through that
// index, before exiting.
stopCh chan uint64
// stepDown is used to indicate to the leader that we
// should step down based on information from a follower.
stepDown chan struct{}
// triggerCh is notified every time new entries are appended to the log.
triggerCh chan struct{}
}In the function
replicate(), callreplicateTo()to do log replication via sending AppendEntries RPC as soon as the leader receives a new command .(After thereplicate()goroutine detects that there is a message intriggerCh, it starts to callreplicate())In the beginning of
replicate(), we start an another new goroutine calling functionheartbeat()to send heartbeat RPC to all the followers periodically.One important issue here is that when 1 new command comes in, the function
replicate()may still be running inreplicateTo()due to previous command. Since the channel size oftriggerChis 1, if new commands come in so fast, we will fail to send the new AppendEntries RPC to followers. To address this issue, we have 2 mechanism:Add a new channel
<-randomTimeout(r.config().CommitTimeout)to send AppendEntries RPC periodically for compendation.Instead of sending empty AppendEntries RPC as the heartbeat RPC, we will carry new
entries[]if we have new command in leader's logs.
When the leader sends AppendEntries to the follower, it will take the adjacent previous log (we don't actually need the Log object, but only need PrevLogIndex and PrevLogTerm for consistency check!). When the follower receives AppendEntries RPC, it will find the previous log entry with same Term and Index.
If it exists and matches, it will accept the log entry; otherwise, after a rejection, the leader decrements nextIndex and retries the AppendEntries RPC. Eventually nextIndex will reach a point where the leader and follower logs match.
Then the follower deletes all the logs after the Index and appends the log entries sent by the leader. Once the logs are appended successfully, all the logs of the follower and the leader are consistent.
Only after the majority of followers respond to receive the log, indicating that the log can be committed, can leader response to client applying successfully.
The Importance of Details
- Follower deleting the existing entry is conditional
Upon receiving a heartbeat, You may truncate the follower’s log following prevLogIndex, and then append any entries included in the AppendEntries arguments. This is not correct. We can once again turn to Figure 2:
If an existing entry conflicts with a new one (same index but different terms), delete the existing entry and all that follow it.
The if here is crucial. If the follower has all the entries the leader sent, the follower MUST NOT truncate its log. Any elements following the entries sent by the leader MUST be kept. This is because we could be receiving an outdated AppendEntries RPC from the leader, and truncating the log would mean “taking back” entries that we may have already told the leader that we have in our log.
- Leaders can only commit logs of their own term
Figure 8 use a time sequence showing why a leader cannot determine commitment using log entries from older terms. To eliminate problems like the one in Figure 8, Raft never commits log entries from previous terms by counting replicas. Only log entries from the leader’s current term are committed by counting replicas.

Coding Hints
- One trick here to implement the rules in Figure 2 for Leaders:
If there exists an N such that
N > commitIndex, a majority ofmatchIndex[i] ≥ N, andlog[N].term == currentTerm: setcommitIndex = N(§5.3, §5.4).
To obtain the majority of matchIndex[i] ≥ N, We can sort matchIndex[] in the increasing order and then fetch the middle one, which is just the N here. And then we can judge if N > commitIndex:
1 | |
- The code have loops that repeatedly check for certain events. Don't have these loops execute continuously without pausing, since that will slow your implementation enough that it fails tests. We insert a time waiting in each loop iteration:
1 | |
If
commitIndex > lastAppliedat any point during execution, we should apply a particular log entry. It is not crucial that you do it straight away (for example, in theAppendEntriesRPC handler), but it is important that you ensure that this application is only done by one entity. Specifically, we have a dedicated “applier”:startApplyLogs(), so that some other routine doesn’t also detect that entries need to be applied and also tries to apply:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36func (rf *Raft) startApplyLogs() {
// dedicated thread calling r.app.apply from Raft
rf.goFunc(func() {
for {
select {
case <- rf.applyLogCh:
// may only be partially submitted
lastApplied := rf.getLastApplied()
for lastApplied < rf.getCommitIndex(){
newLastApplied := lastApplied + 1
msg := ApplyMsg{}
msg.CommandValid = true
msg.SnapshotValid = false
msg.CommandIndex = int(newLastApplied)
entry := rf.getEntryByOffset(newLastApplied)
msg.Command = entry.Data
// Update the last log since it's on disk now
rf.setLastApplied(newLastApplied)
rf.applyCh <- msg
lastApplied = newLastApplied
}
case <-rf.shutdownCh:
rf.logger.Warn("startApplyLogs goroutine shut down!!","peer",rf.me)
return
}
}
})
}
Accelerated Log Backtracking
To optimize accelerated log backtracking, we can follow these steps:
If a follower does not have
prevLogIndexin its log, it should return withconflictIndex = len(log)andconflictTerm = None.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15if lastSnapshotIndex > args.PrevLogIndex || lastLogIndex < args.PrevLogIndex {
reply.Term = currentTerm
reply.Success = false
// If a follower does not have prevLogIndex in its log
// it should return with conflictIndex = lastLogIndex + 1 and conflictTerm = None
reply.ConflictIndex = lastLogIndex + 1
reply.ConflictTerm = 0 //represent conflictTerm = None.
rf.persist()
return
}If a follower does have
prevLogIndexin its log, but the term does not match, it should returnconflictTerm = log[prevLogIndex].Term, and then search its log for the first index whose entry has term equal toconflictTerm.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18func getConflictTermIndex(conflictTerm uint64,logEntries []Log) uint64 {
// all the indexes start from 1, so 0 means no conflict
conflictIndex := uint64(0)
for i:=0; i<len(logEntries); i++ {
if logEntries[i].Term == conflictTerm {
// conflictIndex = uint64(i + 1)
// conflictIndex is the actual index of the log !
conflictIndex = logEntries[i].Index
break
}
}
return conflictIndex
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16if args.PrevLogTerm != prevLogTerm {
reply.Term = currentTerm
reply.Success = false
// If a follower does have prevLogIndex in its log, but the term does not match,
// it should return conflictTerm = log[prevLogIndex - 1].Term
reply.ConflictTerm = prevLogTerm
// then search its log for the first index whose entry has term equal to conflictTerm.
reply.ConflictIndex = getConflictTermIndex(prevLogTerm,originLogEntries)
rf.persist()
return
}Upon receiving a conflict response, the leader should first search its log for
conflictTerm. If it finds an entry in its log with that term, it should setnextIndexto be the one beyond the index of the last entry in that term in its log.If it does not find an entry with that term, it should set
nextIndex = conflictIndex.1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19func (r *Raft) lastConfictTermIndex(conflictTerm uint64) (uint64,bool) {
entries := r.getLogEntries()
founded := false
for i:=0; i<len(entries); i++{
if entries[i].Term==conflictTerm {
founded = true
}
if entries[i].Term > conflictTerm{
//return uint64(i + 1),founded
return entries[i].Index,founded
}
}
return 0,founded
}1
2
3
4
5
6
7
8
9
10
11
12
13
14//If AppendEntries fails because of log inconsistency:
//decrement nextIndex and retry (§5.3)
// The accelerated log backtracking optimization
// Upon receiving a conflict response, the leader should first search its log for conflictTerm.
upperboundIndex, founded := r.lastConfictTermIndex(reply.ConflictTerm)
if founded {
// If it finds an entry in its log with ConflictTerm,
// it should set nextIndex as the one beyond the index of the last entry in that term in its log.
r.leaderState.setNextIndex(reply.ServerID, upperboundIndex)
} else {
r.leaderState.setNextIndex(reply.ServerID, reply.ConflictIndex)
}
Persistence
For the persistent content of the state, it is provided by the Figure 2 at the State part : currentTerm,voteFor and log[]. Besides, in InstallSnapshot, we also need to persist lastIncludedIndex and lastIncludedTerm in order to let server be able to restore the original state after the machine reboots.
1 | |
And of course we should call persist() every time these contents of the state change.
Log Compaction
Raft implements log compaction through snapshot. Server persistently store a "snapshot" of their state from time to time, at which point Raft discards log entries that precede the snapshot.The result is a smaller amount of persistent data and faster restart.
However, it's now possible for a follower to fall so far behind that the leader has discarded the log entries it needs to catch up; the leader must then send a snapshot plus the log starting at the time of the snapshot.
In Raft paper, Figure 12 can be a good illustration of the role of snapshots:
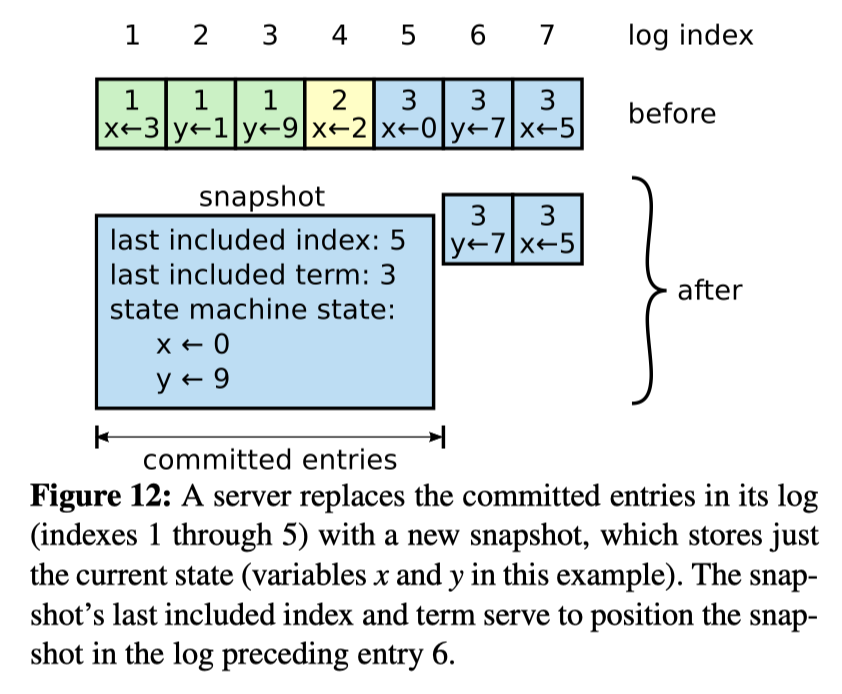
Simple explanation:
Suppose now that the updated information of x and y is stored in the log. The information of x is 3, 2, 0, 5 in sequence. The information of y is 1, 9, and 7 in sequence. And the logs with subscripts 1~ 5 have been committed, indicating that this log is no longer needed for the current node.
Then we access the last stored information as the snapshot (persister.SaveStateAndSnapshot()), that is, x=0, y=9, and record the log index (lastIncludedIndex) of the last snapshot storage and its corresponding term(lastIncludedTerm). At this point, our new logs only store the uncommitted index of 6 and 7, and the length of the logs has changed from 7 to 2.
We can start with the diagram of Raft interactions as mentioned above:
Functions to Implement
Lab 2 require us to implement Snapshot() ,CondInstallSnapshot() and the InstallSnapshot RPC.
Snapshot() is actually called by the service to Raft, so that the Raft node updates its own snapshot information. Some one might argue that this violates Raft's principles of strong leadership. Because followers can update their own snapshots without the leader's knowledge. But in fact, this situation is reasonable. Updating the snapshot is only to update the data, which does not conflict with reaching a consensus. Data still only flows from the leader to the followers, followers just take snapshots to lighten their burden of storage.
The snapshot you send will be uploaded to applyCh, and at the same time your AppendEntries will also need to upload logs to applyCh, , which may cause conflicts. CondInstallSnapshot() is called to avoid the requirement that snapshots and log entries sent on applyCh are coordinated。But in fact, as long as you synchronize well when apply, adding a mutex, then this problem can be avoided. So you are discouraged from implementing it: instead, we suggest that you simply have it return true.
you need to send a InstallSnapshot RPC is actually when the log that the leader sends to the follower has been discarded. We add function leaderSendSnapShot(server int) to send the InstallSnapshot RPC. So whereleaderSendSnapShot() called to send the snapshot should be during consistency check performed by AppendEntries RPCs. The condition is that nextIndex is lower than leader's snapshot: rf.nextIndex[server] < rf.lastIncludeIndex
1 | |
Subscript Tips
Every time you update logs during AppendEntries RPC process, you must take the subscript of the snapshot into count. There are two points you need to take into carefully consideration:
After snapshot, the index(offset) of your log entries
log[]should no longer be euqal toIndexfield of yourtype Log struct. OnlyLog.Indexis actually the global index of all of your log entries.You need to do index conversion everywhere you use
log[]in functions that process RPCs, likefunc (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply)andfunc (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply).For example, if you want to fetch
Termaccording toLog.Index, you can use:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17//get log term by index after snapshot
func (rf *Raft) getLogTermByIndex(index uint64) uint64 {
rf.lastLock.Lock()
var offset int64
offset = int64(index)-int64(1 + rf.lastSnapshotIndex) // may overflow here, caution!!!!
if offset < 0 {
rf.lastLock.Unlock()
return rf.lastSnapshotTerm
}
rf.lastLock.Unlock()
rf.logsLock.Lock()
defer rf.logsLock.Unlock()
return rf.logs[offset].Term
}